The Scarf Tech Stack
At Scarf, we believe open source project maintainers need data in front of them in order to be proactive and do their best work. For example, they need data that answers questions like “how long does it take for our users to adopt a new major version?” To achieve that, we built a system for software distribution with a globally available architecture to passively capture this information and present it to maintainers.

Motivation
At Scarf, we believe open source project maintainers need data in front of them in order to be proactive and do their best work. For example, they need data that answers questions like “how long does it take for our users to adopt a new major version?” To achieve that, we built a system for software distribution with a globally available architecture to passively capture this information and present it to maintainers.
How It Works
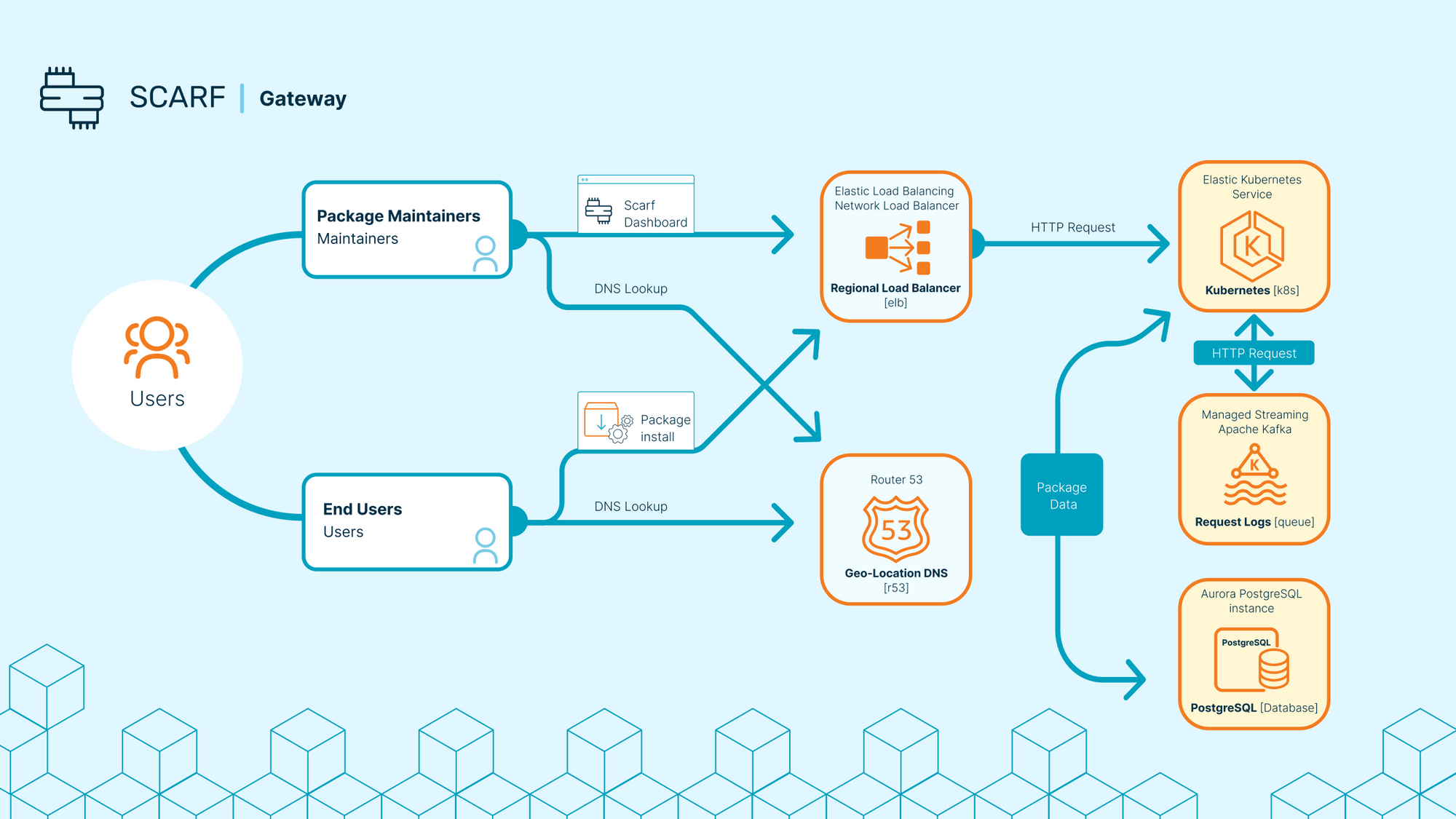
Scarf Gateway is the core of our end-user architecture. Deployed in multiple availability regions on Amazon’s global cloud, it tirelessly serves package content and logs HTTP requests.
Scarf Processor works in the background to read from durable queues of request logs, analyzing the package events derived from multiple HTTP requests. For example, a single Docker container ‘pull’ can result in a dozen HTTP requests hitting a web server. HTTP request logs and the ‘Package Event’ are stored after personally identifiable information is removed. Metrics on Package Events are shared with the maintainer (but without the personal information of any one user.)
Architecture
This blog post is an attempt to share some of the architecture we have developed around Scarf.
AWS Cloud
We exclusively utilize Amazon’s AWS Cloud for development, staging, and production. We originally started out on ECS for Docker containers and an RDS database. Soon after we switched to Kubernetes because of the familiarity factor for most developers we would hire. We felt Kubernetes, in an AWS VPC per region, is a much more robust solution. We still leverage AWS EKS to auto-scale the AWS EC2 nodes for the Kubernetes cluster. This manages the min/max/desired quantity of nodes in the cluster.
Soon after we moved to Kubernetes, we moved from batch processing to stream processing for event data. We needed a durable queue so we used AWS “Managed Streaming for Kafka” and it has been working reliably for us ever since. We process HTTP requests soon after they are queued resulting in faster processing times for Package Events.
We started deploying to multiple AWS Regions last spring and we leverage Route53 Geo-Location DNS. This makes it so clients requesting our services in E.U. use our E.U. cluster and clients in the U.S. use our U.S. cluster, and everyone is being routed to their closest cluster, anywhere in the world.
Build Infrastructure
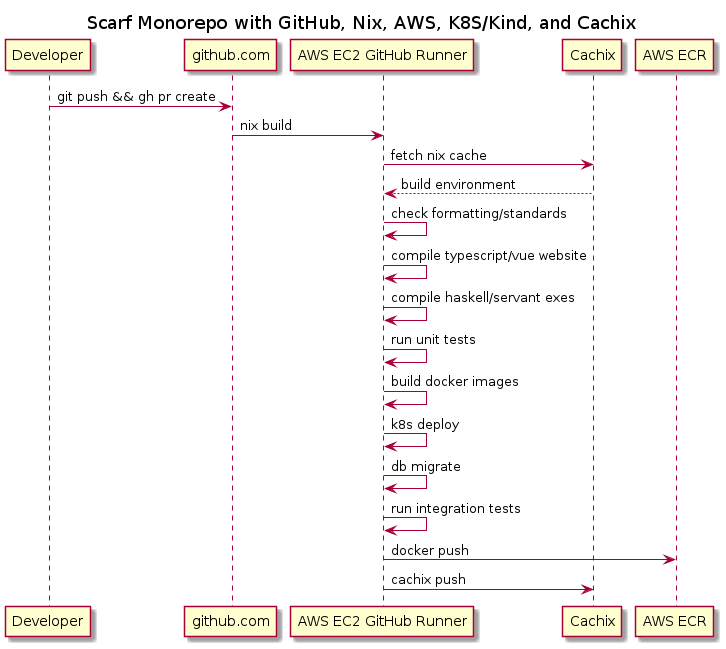
We use GitHub Actions running on a self-hosted GitHub Runner instance on AWS EC2.
We tried using their ephemeral Docker container GitHub Runners but they lacked the ability to cache dependencies. Haskell is known for slower than average compile times. We really need a disk cache of pre-built library dependencies. Stack only caches on disk after the first full compilation of the entire tree from source. So we were stuck using stateful self-hosted GitHub Runner nodes on EC2.
We used to build our Haskell code with Stack and our Typescript/Vue website with Node.js/NPM. Later we replaced Stack with Nix. If you aren’t familiar with Nix, it is a package and build tool that makes it possible to reproduce builds better than most tools. It’s so good at reproducible builds that services like Cachix, which we also began using at the same time, can cache our entire build (in every language.) This makes it so that, if CI builds a branch with a new dependency, there won’t be any need to build that new dependency on every developer’s machine (as would be the case with Stack or NPM.) If we upgrade GHC (Haskell’s compiler) and everything has to be re-compiled from scratch, GitHub Actions and Cachix will handle this for us and we can transparently download all the assets from the cache when the build is done. Compile Once; Use Everywhere (on the same architecture/kernel).
Nix with npmlock2nix also replaced our use of Node.js/NPM directly as build tools. All dependencies for the Node.js are now cached with Cachix.
We added a bit of Go for a Kubernetes extension service we wrote and that is built with Nix also. (The extension allows us to manage hundreds if not thousands of 3rd party domains and TLS certificates directly with Kubernetes’ ingresses & cert-manager. More on this in an upcoming blog post.)
At the same time we switched to Nix, we moved to a “mono-repo” on GitHub. This enables us to keep all of our code together nicely. Haskell, Typescript/Vue/CSS, Go, Terraform, Nix, documents, etc all sit next to each other in the same repository.
We use “Nix shell” environments for development so that all your build tools & libraries for your project are in context in your bash shell. Nix in combination with Direnv makes it possible to ensure ops tools (E.G. Terraform) and project-specific Nix shells are always in your path and available.
Nix also assembles our Docker images for us from the build artifacts. These are cached with Cachix and pushed to AWS ECR during the GitHub Actions build sequence.
In summary, we are highly invested in D.R.Y. when it comes to building and maintaining code, tools, and services. Having one tool to build our entire codebase is an accomplishment.
Operations
Hashicorp’s Terraform is used to manage all of our deployment resources. When it’s time to go to production with our code, we deploy from the command line using `terraform apply` (currently.) Our Terraform setup makes sure that the latest docker images for the branch are built with Nix before deployment and then asserts that all our cloud resources are deployed (including any bump in Docker images for Kubernetes.) We sometimes use k9s and command-line kubectl with kubernetes when needed. Occasionally, we will run our code inside of a local kind cluster (as is done on CI.)
Observability / Monitoring / Alerting
All of our Open Telemetry tracing data is managed by Honeycomb.
Events that warrant getting a SRE in the mix are handled by PagerDuty as is the scheduling of SRE to be available. Our logs are searchable on AWS Cloudwatch. We have also used Prometheus, Loki and Grafana in the past.
In future blog posts we will be going more in-depth about our architecture. If you made it here you should consider working with us!
Can you help us with any of the following?
- Share this on Twitter and let us know your thoughts
- Join the discussion on Hacker News
- Try Documentation Insights and or Scarf Gateway

Beyond the Surface: How to Engage with the Quiet Members of your Open Source Community
In the dynamic realm of community management, marketing, and developer relations, success depends upon more than just attracting attention. It's about fostering meaningful relationships, nurturing engagement, and amplifying your community's impact.
Why Open Source Projects and Companies Should Adopt "Open Source Qualified Leads"
The modern digital age, driven by the proliferation of open-source projects, is as much about community as it is about the code. This means understanding and engaging with potential adopters, contributors, and users becomes critical for the health and success of a project or product. Here enters the concept of "Open Source Qualified Leads" (OQL).

Mastering Telemetry in Open Source: A Simple Guide to Building Lightweight Call Home Functionality
Implementing a call-home functionality or telemetry within open-source software often raises privacy concerns within the community. Many parties, including enterprise security teams, customer advocates, and developers, express rightful apprehensions about the transmission, storage, and usage of data.
